
Introduction
According to a 2025 Gartner report, more than 85% of AI and machine learning projects never reach production, and even among those that do, less than 40% continue to deliver real value after one year. This shows that the biggest challenge is not building AI models, but keeping them useful and reliable in real-world use over time.
The main issue is not the AI model itself, but everything around it like deployment, monitoring, updates, and cost management. Unlike traditional software, AI systems can give different answers for the same input and can slowly become less accurate without any clear errors or warnings. Everything may look fine on the surface, but the system can still be silently giving poor results.
The Silent Failures That Make AI Deployment Different From App Deployment
When a normal software system breaks, it is usually easy to notice. The server may stop working, an error message appears, or the system stops responding. These problems are loud and clear, so teams can quickly fix them. But AI systems are different—they usually fail quietly over time, and the problems are not easy to see with normal monitoring tools.
One common issue is that the AI gives answers that look correct but are actually wrong. Everything may seem fine—the system is running, there are no errors—but the output is still inaccurate. Another problem is “model drift,” where the world changes over time, but the AI does not keep up. It slowly becomes less accurate without anyone noticing, until performance drops badly. A third issue is cost. AI systems use expensive computing power, and even small inefficiencies can quietly lead to very high bills over time without teams realizing it early.
Key Challenges in Implementing AI Services at Production Scale
At scale, AI deployment brings a completely new set of challenges that are very different from traditional software systems. One of the biggest issues is infrastructure complexity. AI systems often rely on powerful GPUs and distributed computing setups, which are much harder to manage than standard servers. As the system grows, coordinating resources across multiple machines becomes increasingly difficult and requires careful planning to avoid inefficiencies and bottlenecks.
Another major challenge is non-deterministic behavior, meaning the same input can produce different outputs at different times, which makes debugging and testing much harder. Along with this, AI systems depend heavily on data, so even small changes in datasets or versions can significantly affect performance, making data management and versioning critical. On top of that, there are observability gaps, where it becomes difficult to truly understand what the model is doing internally or why it made a certain decision. Finally, all of this leads to high operational costs, as running large-scale AI systems requires continuous computing power, monitoring, and optimization, which can quickly become expensive if not carefully managed.
GPU Scheduling Is the First Wall Every AI Deployment Hits
Why Kubernetes Default GPU Allocation Wastes 60–80% of Capacity
Kubernetes treats GPUs as indivisible units, leading to massive underutilization. Most workloads don’t fully consume a GPU, yet cannot share it efficiently.
The “Pod Stuck in Pending” Problem Nobody Warns You About
You scale your deployment—but pods remain stuck due to GPU constraints. This becomes a common bottleneck in AI workloads.
Autoscaling Patterns That Actually Work for LLM Workloads
Autoscaling for LLM workloads requires more specialized strategies than traditional web services because demand is driven by tokens, context length, and inference complexity rather than simple request counts. One effective approach is queue-based autoscaling, where scaling decisions are driven by request backlog and queue depth, ensuring that additional compute resources are allocated when demand starts to accumulate. Another important method is token-aware scaling, which considers the number of input and output tokens per request, allowing the system to scale based on actual compute load rather than just traffic volume. Alongside these, predictive workload scheduling uses historical usage patterns and traffic trends to anticipate demand spikes in advance, enabling proactive scaling before latency issues occur. Together, these patterns create a more responsive and efficient autoscaling system tailored specifically for the unpredictable and compute-heavy nature of LLM workloads.
NVIDIA Dynamo, KAI Scheduler, and the New GPU Scheduling Stack
Modern AI infrastructure is increasingly relying on advanced scheduling systems like NVIDIA Dynamo, KAI Scheduler, and other emerging GPU scheduling stacks to address one of the biggest inefficiencies in large-scale compute: GPU fragmentation. Traditional scheduling approaches often lead to underutilized GPUs, where workloads are unevenly distributed or resources are left partially idle due to rigid allocation rules.
These newer systems introduce smarter allocation strategies that dynamically match workloads to available GPU capacity, improving overall utilization and reducing wasted compute. By understanding workload characteristics in real time—such as memory demand, compute intensity, and concurrency requirements—they can schedule tasks more efficiently across clusters. This results in better throughput, lower costs, and more stable performance for large-scale model serving environments where demand is highly variable.
Leading Approaches to Serving AI Models in Production
Choosing an inference engine for LLM deployment depends heavily on the workload requirements, especially around latency, throughput, and infrastructure constraints. vLLM is primarily optimized for high throughput, making it well-suited for serving large numbers of concurrent requests efficiently through advanced memory management and batching techniques. SGLang focuses more on flexible orchestration, allowing developers to design complex serving workflows and structured generation pipelines with greater control over execution flow. In contrast, TensorRT-LLM is highly optimized for GPU performance, leveraging low-level hardware acceleration and optimizations to achieve minimal latency and maximum efficiency on NVIDIA GPUs. Ultimately, the choice between these engines depends on the specific trade-offs a system must make between speed, cost efficiency, and workload complexity.
Why Triton Terminates When One Model Fails (and How to Prevent It)
In multi-model deployments, a single-point failure can have cascading effects that bring down the entire service if proper isolation is not enforced. When multiple models share the same infrastructure, runtime, or dependencies, a failure in one component—such as memory overflow, corrupted inference, or dependency crash—can propagate and impact other models running in the same environment. This makes isolation a critical design principle.
To mitigate this risk, strong container-level fault handling is essential. By running models in separate containers with defined resource limits and isolated execution environments, failures can be contained without affecting the broader system. This approach ensures that one model’s instability does not compromise overall service availability, enabling more resilient and fault-tolerant multi-model architectures in production.
Disaggregated Prefill/Decode Architectures Explained
Separating prefill and decode phases in LLM serving significantly improves efficiency, particularly in high-concurrency environments. The prefill stage, which processes the input prompt and builds the initial context, is typically compute-heavy and benefits from batching and parallel execution. In contrast, the decode stage generates tokens sequentially and is more latency-sensitive, often becoming the bottleneck under load. By decoupling these two phases, systems can optimize resource allocation—running prefill in high-throughput batches while dedicating stable, low-latency resources to decode. This separation reduces contention, improves GPU utilization, and leads to more predictable performance when serving multiple simultaneous requests.
When to Use KServe, BentoML, or Ray Serve
Modern model serving frameworks are increasingly designed to handle different layers of complexity in production AI systems. KServe focuses on Kubernetes-native deployments, enabling scalable and standardized model serving directly within Kubernetes clusters, making it ideal for cloud-native infrastructure and enterprise environments. In contrast, BentoML prioritizes developer-friendly packaging, allowing data scientists and engineers to easily package, version, and deploy models with minimal operational overhead, which simplifies the path from experimentation to production. Meanwhile, Ray Serve is built for distributed serving at scale, leveraging the Ray ecosystem to efficiently handle high-throughput, low-latency inference across multiple nodes, making it suitable for large and dynamic workloads. Together, these tools reflect different approaches to solving the same challenge—deploying and serving machine learning models reliably in production at scale.
Best Practices for AI Model Versioning and Updates in Production
Why MLflow Deprecating Model Stages Broke Everyone’s Pipeline
Many AI pipelines traditionally depended on staging environments as a safety layer to validate changes before production, but removing this layer forces teams to fundamentally rethink how they manage version control and promotion strategies. Without a dedicated staging step, there is less room for manual verification, making it essential to adopt stronger automation, stricter versioning practices, and more reliable testing mechanisms. Teams must rely on techniques like immutable artifacts, automated validation pipelines, and progressive deployment strategies to ensure that what reaches production is stable and trustworthy. This shift ultimately pushes organizations toward more disciplined, reproducible workflows where every change is traceable, tested, and safely promotable without relying on a separate staging environment
GitOps for Model Deployment: What Works and What Doesn’t
While GitOps is highly effective for managing infrastructure through version-controlled, declarative workflows, it struggles when applied to AI systems that involve large model artifacts and complex data dependencies. Git repositories are not built to efficiently handle massive binary files like trained models, making storage and versioning difficult, and they also fall short in tracking evolving datasets and feature transformations that are critical to model behavior. Unlike infrastructure configurations, these components change frequently and are harder to reproduce consistently across environments, leading to potential mismatches between training and production. As a result, GitOps alone is not sufficient for AI workflows and must be complemented with specialized solutions for model storage, data versioning, and experiment tracking to maintain reliability and reproducibility.
Shadow Deployments, Canary Releases, and Safe Rollback Patterns
Production-safe deployment patterns are essential for reducing risk when introducing new models or updates into live environments. Instead of pushing changes all at once, these approaches allow teams to validate performance, monitor impact, and respond quickly to issues without disrupting users.
One key strategy is shadow testing, where the new model runs alongside the existing one in production without affecting real users. This allows teams to compare outputs, validate behavior, and identify potential issues using real-world data before fully deploying the model. Another important approach is canary releases, which involve gradually rolling out the new model to a small subset of users. This controlled exposure helps detect problems early while minimizing the overall impact if something goes wrong.
Equally critical are instant rollback mechanisms, which ensure that systems can quickly revert to a previous stable version if performance degrades or unexpected errors occur. Together, these deployment patterns create a safety net, enabling teams to innovate and iterate faster while maintaining stability, reliability, and user trust in production systems.
AI Deployment Tracking: Building an Audit Trail Across Code, Data, and Weights
Effective tracking in AI systems must go beyond basic logging and include every component that influences model behavior in production. This starts with the model version, ensuring you know exactly which iteration of the model is running at any given time. Alongside that, the dataset version is equally critical, as even small changes in training data can significantly impact performance and outcomes.
Another key aspect is feature transformations, which define how raw data is processed before being fed into the model. Any inconsistency in these transformations between training and production can lead to incorrect predictions. Equally important is the deployment environment, including infrastructure, dependencies, and configurations, all of which can subtly affect how the model behaves in real-world conditions.
Without tracking all of these elements together, debugging becomes nearly impossible. When something goes wrong, teams are left guessing which component caused the issue, leading to longer resolution times and unreliable systems. Comprehensive tracking ensures traceability, reproducibility, and faster diagnosis of problems in complex AI workflows.
Fastest Way to Deploy Generative AI Model Into Production Safely
The fastest path to reliable AI deployment is not about cutting corners or skipping critical steps, but about systematically automating them. As systems grow in complexity, manual processes become bottlenecks and introduce inconsistencies, which can slow down development and increase the risk of errors in production.
This is where pre-configured environments play a crucial role, ensuring that development, testing, and production setups remain consistent from the start. By standardizing dependencies, configurations, and infrastructure, teams can eliminate environment-related issues that often cause failures during deployment. Alongside this, built-in version control helps track changes across models, datasets, and code, making it easier to reproduce results, roll back updates, and maintain transparency throughout the lifecycle.
Equally important are automated validation pipelines, which continuously test models against defined benchmarks and real-world scenarios before deployment. These pipelines help catch issues early, enforce quality standards, and ensure that every update meets performance and reliability expectations. Together, these elements create a streamlined and dependable workflow, allowing teams to move faster without compromising on quality or stability.
Best Practices for Deploying Foundation Models at Scale
As models scale beyond tens of billions of parameters, single node inference is no longer sufficient, and systems must shift to multi-node inference architectures. At the 70B+ parameter level, inference requires distributing computation across multiple GPUs or machines, which introduces new challenges such as network latency, inter-node communication overhead, and synchronization complexity. These factors can significantly impact response times, making system design far more critical than in smaller-scale deployments.
Another major concern in production is KV cache management. Large models rely heavily on key-value caching to speed up token generation, but if this cache is not handled efficiently, it can lead to memory fragmentation and wasted GPU resources. Over time, this reduces throughput and increases latency, especially under high-concurrency workloads, making proper memory planning and cache optimization essential for stable performance.
To handle the computational load, different parallelism strategies are used, each with its own trade-offs. Tensor parallelism splits model computations across GPUs but is often limited by the speed of communication between them, creating bottlenecks at scale. Pipeline parallelism, on the other hand, divides the model into stages across devices, which helps with memory distribution but introduces latency due to sequential processing. In practice, hybrid approaches that combine both techniques tend to offer the best balance, optimizing for both performance and resource utilization.
Cold start problems also become much more pronounced with large foundation models. Unlike smaller services, these models cannot easily scale down to zero because of their heavy memory requirements and long initialization times. Loading a massive model into memory can take significant time, leading to delays in handling the first request and making it difficult to achieve true on-demand scaling.

CI/CD for ML Models — Where Traditional Pipelines Silently Fail
One of the most overlooked yet critical challenges in deploying AI systems is training-serving skew, often considered the silent killer of production performance. This occurs when there is a mismatch between the environment in which a model is trained and the one in which it is deployed. Even small differences in data formats, preprocessing steps, or feature availability can lead to significant drops in model accuracy and reliability, making a well-trained model behave unpredictably in real-world scenarios.
This is why the common assumption that you can “just containerize the model” falls short. While containerization ensures that the model code runs consistently, it does not account for the broader ecosystem the model depends on. In reality, models are tightly coupled with data pipelines, feature engineering logic, and external services such as APIs or databases. If any of these components behave differently in production compared to training, the model’s outputs can become unreliable despite being technically “deployed correctly.”
A related issue arises with feature stores, where maintaining consistency and reproducibility across environments becomes essential. If the features used during training are not generated in exactly the same way during inference, predictions can break or become inaccurate. Even slight discrepancies in feature values or transformations can cascade into major performance issues, making it crucial to have strict controls and validation around feature generation.
Compounding this complexity is the challenge of testing non-deterministic systems like large language models or probabilistic AI systems. Traditional testing methods are not sufficient here. Instead, testing must include statistical validation to evaluate performance trends over time, output consistency checks to ensure stable behavior across similar inputs, and edge case simulations to understand how the system performs under unusual or extreme conditions. Together, these practices help build more resilient AI systems that can handle the unpredictability of real-world deployment.
LLM Observability Requires a Monitoring Stack Built From Scratch
Why APM Tools Miss Hallucinations Returning HTTP 200
Traditional monitoring systems are primarily designed to track the health and performance of infrastructure rather than the quality of what an AI model actually produces. They focus on metrics such as uptime, latency, error rates, and resource utilization, which are essential for ensuring that systems are running smoothly and efficiently. However, these indicators only reveal whether the system is operational—not whether the outputs are accurate, meaningful, or trustworthy.
This creates a significant gap when dealing with AI models, especially large language models, where the real value lies in the quality of responses. A system can show perfect uptime and low latency while still generating incorrect, inconsistent, or misleading outputs. As a result, relying solely on traditional monitoring is insufficient for modern AI applications, where evaluating output quality, reasoning, and reliability is just as critical as maintaining system performance..
Detecting Model Drift Before Business Metrics Crater
Drift detection in modern AI systems is not a one-time check but an ongoing process that ensures model behavior remains stable and reliable over time. It requires continuous evaluation, where the model is regularly tested against new inputs and real-world scenarios to identify any changes in performance, accuracy, or reasoning quality. This helps detect when the model starts deviating from its expected behavior due to evolving data patterns or shifting user interactions.
Another critical component is feedback loops, which allow systems to learn from user interactions, corrections, and observed failures. These loops help refine model responses over time by feeding real-world signals back into the evaluation process, making the system more adaptive and self-improving. Alongside this, benchmark datasets play a key role by providing a stable reference point to compare model performance consistently. They act as a control group, helping teams measure whether changes in the model lead to improvements or unintended degradation. Together, these three elements form the foundation of effective drift detection in modern AI systems.
Semantic Monitoring, Grounding Scores, and Faithfulness Metrics
In modern AI systems, evaluation is moving beyond basic performance metrics toward deeper measures that better reflect how models actually think and respond. Instead of focusing only on speed or output correctness, attention is now placed on understanding the quality of reasoning, reliability of information, and alignment with user intent.
A key part of this shift includes accuracy of meaning, which checks whether the model correctly understands the intent behind a prompt rather than just producing a plausible answer. Alongside this is source grounding, which ensures responses are backed by reliable and verifiable information, reducing hallucinations and improving trust. Another important factor is logical consistency, which evaluates whether the model maintains coherent and contradiction-free reasoning across its output.
Together, these aspects form the foundation of the emerging LLM observability stack, a new generation of tools that provide deeper visibility into AI behavior. Unlike traditional logs and metrics, these systems help developers understand not just what the model produces, but how and why it generates those outputs, enabling more reliable and transparent AI systems
Challenges of Deploying AI Assistants in Large Organizations
Only a small percentage of so-called “enterprise agents” are truly autonomous, with many implementations being little more than scripted workflows rather than intelligent, decision-making systems. While they may appear sophisticated on the surface, these setups often lack the adaptability and reasoning capabilities that define real agents, leading to inflated expectations and limited real-world effectiveness.
Tool sprawl becomes a serious problem when businesses grow their systems, particularly when agent performance starts to suffer from integrating too many tools. After a given number of integrations—typically around 20—latency rises, dependability declines, and coordination becomes more difficult, which eventually lowers the system’s overall efficiency.
At the same time, enterprise-grade deployments must address challenges like multi-tenant isolation, rate limiting, and cost attribution. These controls are critical to ensure that resources are allocated fairly, usage is monitored accurately, and costs are tracked at a granular level across teams or customers, preventing misuse and maintaining system stability.
Agent orchestration also introduces new failure modes, particularly in complex, non-deterministic environments. This is where human-in-the-loop patterns become essential, allowing human oversight in high-risk or ambiguous scenarios. By combining automation with human judgment, organizations can reduce errors and improve decision quality.
In addition, AI-driven systems require a new approach to incident management. Traditional runbooks are no longer sufficient for handling unpredictable agent behavior, so teams must develop adaptive incident response strategies tailored to non-deterministic systems. This includes monitoring for unusual patterns, defining escalation paths, and preparing for edge cases that may not have clear, predefined solutions.
Inference Cost Management — The New FinOps Frontier
GPU costs often catch teams off guard when moving AI workloads into production, primarily because expenses scale directly with usage—and any inefficiencies quickly amplify those costs. What seems manageable during experimentation can become significantly expensive at scale, especially when workloads are not optimized or resources are over-provisioned.
To manage this effectively, understanding unit economics becomes essential. Breaking down costs into metrics like cost per inference, per conversation, or per feature allows teams to identify where money is being spent and where optimizations can be made. This level of granularity provides clearer visibility and enables more informed decision-making around performance and cost tradeoffs.
Techniques such as prompt caching, model routing, and quantization play a crucial role in cost optimization. By reducing redundant computations, selecting the most efficient models for each task, and compressing model sizes without heavily impacting performance, teams can significantly lower their overall infrastructure expenses while maintaining acceptable output quality.
Another common challenge is idle GPU costs and inefficient scaling practices. Even when GPUs are not actively processing workloads, they continue to incur costs if left running. Without proper scaling strategies—such as automatic scale-down or workload-based provisioning—organizations can end up paying for unused resources, making efficient resource management a critical component of sustainable AI operations.
Edge AI Deployment: When the Cloud Isn’t an Option
Model quantization and distillation are key techniques for enabling AI on edge devices with limited hardware. By reducing model size and complexity while preserving performance, they allow efficient inference on constrained systems like mobile devices and IoT hardware.
Over-the-air (OTA) model updates must be carefully designed to prevent device failures. Safe update mechanisms such as versioning, rollback options, and staged rollouts ensure models can be deployed without risking system stability.
Edge-to-cloud hybrid patterns help balance speed and scalability by running lightweight inference locally while offloading heavier tasks to the cloud. This improves responsiveness while still leveraging cloud capabilities when needed.
Observability and drift detection remain challenging on disconnected devices, where continuous monitoring is not possible. Teams rely on local logging, periodic synchronization, and lightweight monitoring strategies to track performance and detect model drift over time.

Key Challenges in Implementing Responsible AI in Production
AI systems functioning at scale increasingly require guardrails, PII redaction, and input/output filtering. Enforcing security and privacy in real time is becoming essential as models engage with real-world data. While preserving the integrity and use of AI outputs, organisations must make sure that sensitive material is automatically identified, concealed, or restricted.
At the same time, audit logging, data lineage, and regulatory compliance are gaining significant importance as AI adoption grows. Businesses are now expected to maintain full traceability across the entire AI lifecycle, from data ingestion to model decisions. This level of transparency not only helps meet regulatory requirements but also builds trust by enabling teams to understand, explain, and verify how AI systems operate.
In parallel, bias monitoring and fairness evaluation are critical to ensuring responsible AI deployment. Models must be continuously assessed for unintended biases that could impact decision-making and user outcomes. This requires ongoing evaluation, feedback loops, and refinement to ensure fairness, inclusivity, and ethical alignment in production environments.
Red-teaming and jailbreak detection are emerging as proactive strategies to secure AI systems in production. Instead of waiting for vulnerabilities to be exploited, organizations are actively testing their models against adversarial inputs and misuse scenarios. This approach helps identify weaknesses early, strengthen defenses, and ensure that AI systems remain robust, reliable, and safe under real-world conditions.
The MLOps Tool Sprawl Problem That Keeps Getting Worse
Internal ML platforms often turn into costly investments over time, as custom-built solutions demand continuous maintenance, updates, and scaling efforts. What may start as a strategic advantage can quickly become a resource drain, requiring dedicated teams to manage infrastructure, resolve issues, and keep systems aligned with evolving requirements.
At the same time, security vulnerabilities in ML frameworks present serious challenges, especially when systems are left unpatched or outdated. These gaps can expose organizations to critical risks, including data breaches and model exploitation, making ongoing security management a non-negotiable aspect of ML operations.
As a result, teams are increasingly shifting toward a converging standard stack that emphasizes consistency and integration. Rather than relying on fragmented tools, organizations are adopting unified platforms that streamline workflows, improve interoperability, and reduce operational overhead.

What the Next 12 Months Look Like for AI Deployment
Kubernetes-native inference is rapidly becoming the standard as AI workloads increasingly align with modern cloud-native architectures. Organizations are no longer treating AI as a separate layer but are integrating it directly into their existing Kubernetes ecosystems to ensure scalability, portability, and efficient resource utilization. This shift allows teams to deploy, manage, and scale models just like any other microservice, making AI operations more consistent and production-ready.
At the same time, AI-powered incident response is emerging as a key advancement in Site Reliability Engineering (SRE). Instead of relying solely on manual monitoring and reactive troubleshooting, teams are beginning to leverage AI-driven automation to detect anomalies, predict potential failures, and even resolve incidents in real time. This not only reduces downtime but also frees up engineering teams to focus on higher-value tasks rather than constant firefighting.
Platform engineering is converging with AI to create unified systems that simplify complex operations. The future lies in building integrated platforms where infrastructure, workflows, and AI capabilities coexist seamlessly. Such platforms abstract away underlying complexities, enabling developers and organizations to innovate faster while maintaining control, security, and scalability across their AI initiatives.

How Gripo Flow Solves AI Deployment Challenges in Seconds
Launch AI Workflows in a Secure, Isolated Environment
Gripo Flow gives you a fully isolated sandbox where you can build, test, and deploy AI workflows without risking your core systems. Run anything—models, APIs, or agents—safely and independently.
One-Click Deployment, Zero Infrastructure Hassle
Just click deploy and your workflow runs in a secure, pre-configured environment instantly.
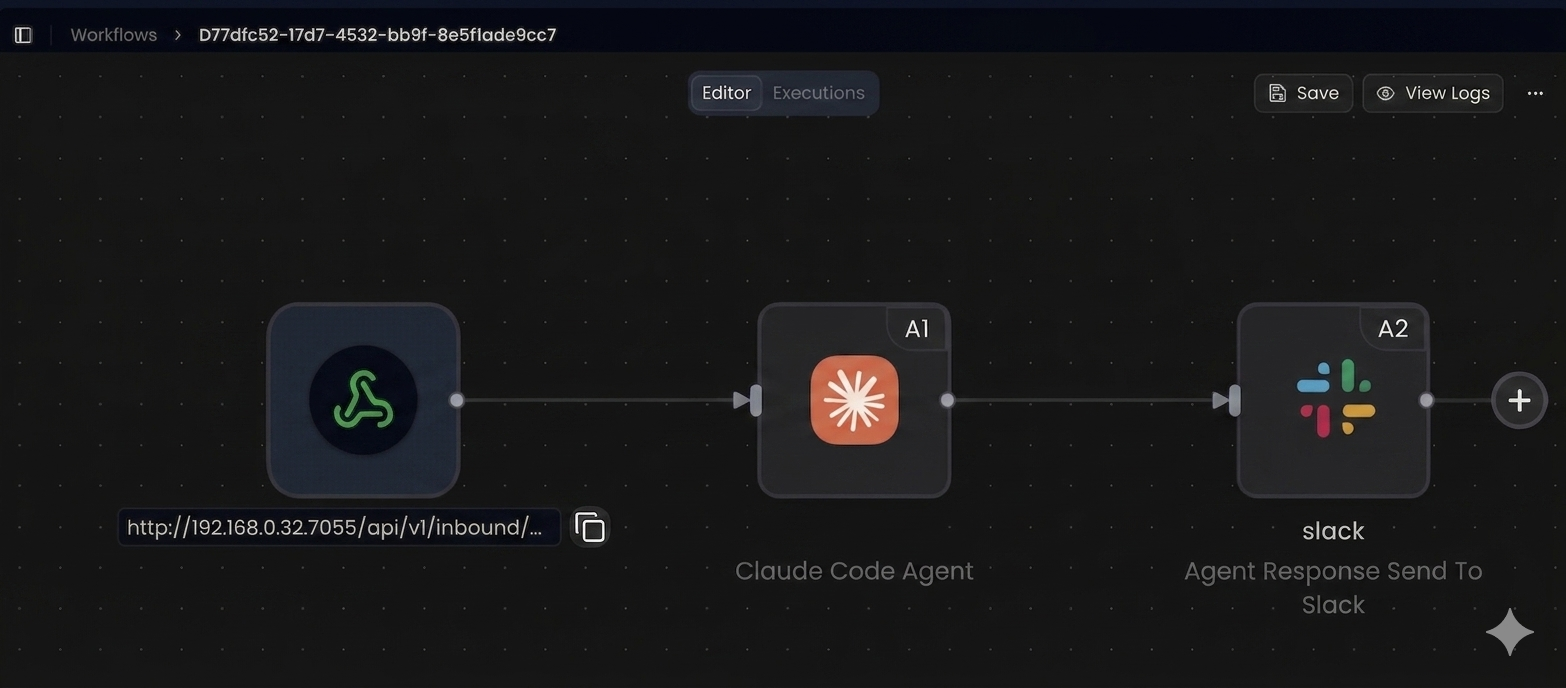
Build, Secure, Monitor, and Deploy AI Workflows in a Unified Sandbox Environment
Gripo Flow enables teams to create complete AI pipelines using an intuitive drag-and-drop workflow builder, without requiring deep DevOps or infrastructure expertise. This makes it significantly easier for developers, data teams, and even non-technical users to design, test, and deploy workflows with minimal effort. By removing the traditional barriers of setting up and managing complex infrastructure, Gripo Flow helps teams focus more on building logic and solving real problems instead of dealing with configuration overhead, deployment issues, or system-level complexity. This leads to faster experimentation, quicker iteration cycles, and much smoother execution of AI workflows.
Beyond just visual workflow creation, Gripo Flow also provides strong operational visibility and control. Users can track data usage and cost in real time, ensuring that AI workloads remain efficient and predictable. Intelligent alerts help teams quickly identify unusual usage patterns, performance issues, or cost spikes before they become serious problems. Most importantly, all workflows run inside a secure, fully isolated sandbox environment, where AI agents can safely perform tasks like coding, automation, testing, and deployment. This allows teams to experiment freely and even deploy real applications without risking production systems, giving them both speed and security in one unified platform.
Conclusion
The Real Gap Isn’t Model Quality . It’s Operational Maturity
Most teams don’t fail because of bad models—but because of weak deployment systems.
Your First Three Moves
- Audit GPU usage
- Track unit economics
- Implement LLM observability
FAQ
What are the biggest AI model deployment challenges in production?
GPU scaling, observability, cost management, and model versioning are the most critical challenges.
Why do most AI deployments fail to reach production?
Because of infrastructure complexity, lack of monitoring, and inability to handle non-deterministic behavior.
What’s the fastest way to deploy a generative AI model into production?
Using pre-built platforms with automated workflows, versioning, and deployment pipelines.
How do you track AI model deployments across environments?
By maintaining a unified audit trail of code, data, and model versions.
What are best practices for AI model versioning in production?
Use GitOps, automated rollbacks, and structured deployment strategies like canary releases.
How do large organizations deploy AI assistants safely?
Through isolation, monitoring, human oversight, and strict governance policies.
What are the leading approaches to serving AI models in production?
Inference engines like vLLM, TensorRT-LLM, and orchestration tools like KServe or Ray Serve.
How is edge AI deployment different from cloud deployment?
Edge deployment focuses on low latency, limited resources, and offline capabilities.
How does Gripo Flow simplify AI deployment compared to custom pipelines?
It removes infrastructure complexity, automates workflows, and provides built-in deployment, tracking, and testing tools.